[KB2D]
Program [KB2D] służy do estymacji metodami prostego i zwykłego krigingu (SK i OK) dla danych dwuwymiarowych (oczywiście także jednowymiarowych). Jest to prosty algorytm, pozbawiony szeregu zaawansowanych opcji definiowania sąsiedztwa szukania (search neigborhood), oraz testowania jakości estymacji (kroswalidacja, walidacja podzbioru).
Wzorcowy (blank) plik
parametrów
Plik parametrów z objaśnieniami po polsku
Uwaga: W efekcie działania [KB2D] uzyskuje się dwa pliki z wynikami obliczeń:
Ø Pierwszy z nich to plik tekstowy (ASCII) zawierający rejestrację etapowych wyników obliczeń. W pliku parametrów podaje się tak zwany „debugging level” w zakresie od 0 do 3. Im wyższa jego wartość, tym więcej wyników jest rejestrowane. Jeśli siatka interpolacyjna jest duża (dziesiątki tysięcy węzłów i więcej) oraz wybrano poziom 2 lub 3, to rozmiar wynikowego pliku może być bardzo duży (dziesiątki MB i więcej). Wysoki poziom rejestracji wybiera się wówczas, kiedy trzeba przeprowadzić analizę macierzy estymacji krigingowych dla poszczególnych węzłów siatki interpolacyjnej w celu identyfikacji przyczyn nieoczekiwanych rezultatów.
Ø Drugi to plik tekstowy (ASCII) w uproszczonym formacie Geo-EAS z dwoma kolumnami danych: wartości estymowanych i wariancji krigingowych dla kolejnych węzłów siatki interpolacyjnej. Są one pozbawione współrzędnych i uporządkowane najpierw według rosnących wartości współrzędnej Y, a później według rosnącego X. Tak uporządkowane dane można za pomocą programu [PIXELPLT] przedstawiać w postaci map rastrowych
Fragment zawartości pliku rejestracji etapowych wyników obliczeń metodą prostego krigingu (SK) przy „debugging level” równym 2.
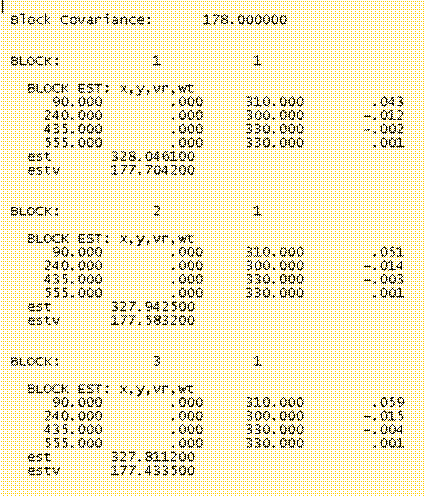
Ø Algorytm
zawarty w programie [KB2D] umożliwia
wykonanie zarówno estymacji punktowych (point
kriging), jak i blokowych (block kriging). Block kriging to nazwa własna procedur umożliwiających
szacowanie średniej wartości dla fragmentu profilu, wycinka powierzchni czy
objętości o dowolnym rozmiarze i kształcie. Potrzeby uzyskania takich wartości
są zazwyczaj praktyczne. Dla rolnika nie jest ważne jakie
są właściwości gleby w określonym punkcie pola. Ze względu na rodzaj urządzeń którymi się posługuje do nawożenia, nawadniania,
czy też siania interesuje go średnia wartość cechy gleby na powierzchni równej
zwykle kwadratowi szerokości tzw. „pasa uprawy”, czyli w warunkach polskich ok.